Deep Dive in to Catalyst Optimizer -Apache Spark
Spark has become the de-facto framework for big data processing and machine learning . Community has adapted it a lot that any new development in the world of big data is going to be spark only.
Evolution of Spark APIs and their features are depicted in the picture below

RDD Challenges:
RDD is the low-level API in spark programming, like Java code for MapReduce. Up until Spark2, there was only RDD as a spark core component. If things are not handled properly while dealing with RDD, performance can take a big hit.
Dataframe - The next age high-level API.
One major change in Spark2 is the introduction of Dataframes and Datasets(Remember there is no concept of dataset in pyspark,becasue dataset is a typed object , which is suitable in object oriented programming only, like Scala and Java)
Catalyst Optimizer :
When SparkSQL ,Dataframe,Dataset are used, Catalyst Optimizer kicks in to convert the code into an optimal RDD code , which is the basic building block of Spark.
Unless one is an expert in RDD coding, its strongly recommended to use Dataframe/Dataset in order to get benefited from Catalyst Optimizer as it generates multiple physical plans out of a logical plan and picks the best physical plan according to the Time and complexity.
The internals :
Trees : In every dataframe operation , the lowest leaflets are decided and then the parent nodes. Basically the logical plan is created from bottom up. Unresolved logical plan will have what will be the input and what needs to be produced as an output
Physcial planning:
BroadcastJoin : (Keeping the small size table or dataset in the memory to avoid disk I/O when dealing with a large dataset fact table and small dataset dimension table, its referred to mapjoin in hadoop framework)
HashJoin : (The default join implementation in spark, it will be expensive at times becasue it shuffles a lot to merge the data with same partition key into one place.)
PredicatePushDown ( applying filters before joining,selecting only specific partition etc)
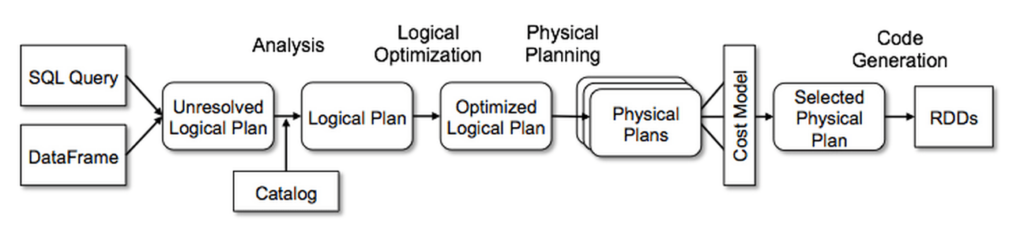
Cost Based optimal plan selection :
Time and complexity of each of the generated physical plans are evaluated and the optimal physical plan is chosen based on the cost. Same is then transferred into a RDD code.

Comments
Post a Comment